| 《python解释器源码剖析》第8章 | 您所在的位置:网站首页 › python interpreter source code › 《python解释器源码剖析》第8章 |
《python解释器源码剖析》第8章
|
8.0 序
我们日常会写各种各样的python脚本,在运行的时候只需要输入python xxx.py程序就执行了。那么问题就来了,一个py文件是如何被python变成一系列的机器指令并执行的呢? 8.1 python程序的执行过程python的执行原理可以用两个词来囊括:虚拟机、字节码 首先在python中有一个非常关键的东西,这个东西被称为解释器(interpreter),当我们在命令行中输入python时,就是为了激活这个解释器。当然如果后面还跟上了py文件,那么解释器会立刻被激活,然后执行py文件里面的代码。然而在真正开始执行之前,解释器实际上还要完成一个非常复杂的工作--编译py文件 没错,python虽然是解释型语言,但也是有编译的过程的。无论执行哪一个py文件,首先都是对源代码进行编译,编译成一组python的字节码(byte code),然后将编译的字节码交给python的虚拟机(virtual machine),然后由虚拟机按照顺序一条一条地执行字节码,从而完成对python执行动作。关于虚拟机和解释器的区别,个人觉得在python中可以认为解释器 = 编译器 + 虚拟机。不要误会这里的编译器,这只是编译成python中的字节码,可不是C语言中直接编译成机器码的解释器。 那么这个python的编译器和虚拟机藏身于什么地方呢?我们打开python的安装目录,会看到一个python.exe,点击的时候确实能启动一个终端,但是这个文件大小还不到100K,不可能容纳一个解释器加一个虚拟机。但是事实上你会发现,下面还有一个python37.dll,没错,编译器、虚拟机都藏身于python37.dll当中。 8.2 python编译器的编译结果--PyCodeObject对象 8.2.1 PyCodeObject对象和pyc文件我们来看一个简单的例子,来看看一个py文件被编译之后应该产生一些什么结果 class A: pass def foo(): pass a = A() foo()首先我们知道,python执行这个文件首先要进行的动作就是编译,编译的结果是字节码。然而除了字节码之外,还应该包含一些其他的信息,这些结果也python运行的时候所必须的。 在编译过程中,像常量值、字符串这些源代码当中的静态信息都会被python编译器收集起来,这些静态信息都会体现在编译之后的结果里面。在python运行期间,这些源文件提供的静态信息都会被存储在一个运行时的对象当中,当python运行结束时,这个运行时对象中所包含的信息还会被存储在一种文件中。这个对象和文件就是我们接下来要探讨的重点:PyCodeObject对象和pyc文件 我们知道编译的结果是一个pyc文件,但是里面的内容是PyCodeObject对象,对于python编译器来说,PyCodeObject对象才是其真正的编译结果,而pyc文件是这个对象在硬盘上表现形式。因此它们实际上是python对源代码编译之后的两种不同的存在形式。 在程序运行期间,编译结果存在于内存的PyCodeObject对象当中,而python结束运行之后,编译结果又被保存到了pyc文件当中。当下一次运行的时候,python会根据pyc文件中记录的编译结果直接建立内存中的PyCodeObject对象,而不需要再度重新编译了。 8.2.2 python源码中的PyCodeObject对象关于python是如何编译py文件的,这个我们不做介绍,因为这还涉及分词、建立语法树等等,我们的重点是编译之后的结果。要彻底理解python虚拟机的运行时行为,就必须彻底理解PyCodeObject对象。 /* Bytecode object */ typedef struct { PyObject_HEAD int co_argcount; /* #arguments, except *args */ int co_kwonlyargcount; /* #keyword only arguments */ int co_nlocals; /* #local variables */ int co_stacksize; /* #entries needed for evaluation stack */ int co_flags; /* CO_..., see below */ int co_firstlineno; /* first source line number */ PyObject *co_code; /* instruction opcodes */ PyObject *co_consts; /* list (constants used) */ PyObject *co_names; /* list of strings (names used) */ PyObject *co_varnames; /* tuple of strings (local variable names) */ PyObject *co_freevars; /* tuple of strings (free variable names) */ PyObject *co_cellvars; /* tuple of strings (cell variable names) */ /* The rest aren't used in either hash or comparisons, except for co_name, used in both. This is done to preserve the name and line number for tracebacks and debuggers; otherwise, constant de-duplication would collapse identical functions/lambdas defined on different lines. */ Py_ssize_t *co_cell2arg; /* Maps cell vars which are arguments. */ PyObject *co_filename; /* unicode (where it was loaded from) */ PyObject *co_name; /* unicode (name, for reference) */ PyObject *co_lnotab; /* string (encoding addrlineno mapping) See Objects/lnotab_notes.txt for details. */ void *co_zombieframe; /* for optimization only (see frameobject.c) */ PyObject *co_weakreflist; /* to support weakrefs to code objects */ /* Scratch space for extra data relating to the code object. Type is a void* to keep the format private in codeobject.c to force people to go through the proper APIs. */ void *co_extra; } PyCodeObject;这里面的每一个域代表什么,可以暂时无需理会,我们后面会一一介绍,但是里面有一个co_code可以提前剧透一下,这个域存放的是编译所生成的字节码指令序列。 python编译器在对python源代码进行编译的时候,对于代码中的每一个block,都会创建一个PyCodeObject与之对应,但如何确定多少代码才算是一个block呢?事实上,python有一个简单而清晰的规则:当进入一个新的名字空间,或者说作用域时,我们就算是进入了一个新的block了。 回顾之前创建的py文件,在编译完之后会有三个PyCodeObject对象,一个是对应整个py文件的,一个是对应class A的,一个是对应def foo的。 在这里,我们开始提及python中一个至关重要的概念--命名空间(name space)。命名空间是符号的上下文环境,符号的含义取决于命名空间。更具体的说,一个变量名对应的变量值什么,在python中是不确定的,需要命名空间来决定。 对于某个符号,比如说a,在某个命名空间中,它可能是一个PyLongObject对象;而在另一个命名空间中,它可能是一个PyListObject对象。但是在一个命名空间中,一个符号只能有一种含义。而且命名空间可以一层套一层的形成一条命名空间链,python虚拟机在执行的时候,会有很大一部分时间消耗在从命名空间链中确定一个符号所对应的对象是什么。这也侧面说明了,为什么python在创建变量的时候不需要指定类型、以及python为什么比较慢。 如果现在命名空间还不是很了解,不要紧,随着剖析的深入,你一定会对命名空间和python在命名空间链上的行为有越来越深刻的理解。总之现在需要记住的是:一个code block对应一个命名空间、同时也对应一个PyCodeObject对象。在python中,类、函数、module都对应着一个独自的命名空间,因此都会有一个PyCodeObject与之对应。 8.2.3 pyc文件每一个PyCodeObject对象中都包含了每一个code block中所有代码经过编译后得到的byte code序列。前面我们说到,python会将字节码序列和PyCodeObject对象一起存储在pyc文件中。但不幸的是,事实并不总是这样。有时,当我们运行一个简单的程序时并没有产生pyc文件,因此我们猜测:有些python程序只是临时完成一些琐碎的工作,这样的程序仅仅只会运行一次,然后就不会再使用了,因此也就没有保存至pyc文件的必要。 如果我们在代码中加上了一个import abc这样语句,再执行你就会发现python为其生成了pyc文件,这就说明import会触发pyc的生成。实际上,在运行过程中,如果碰到import abc这样的语句,那么python会在设定好的path中寻找abc.pyc或者abc.dll文件,如果没有这些文件,而是只发现了abc.py,那么python会先将abc.py编译成PyCodeObject,然后创建pyc文件,并将PyCodeObject写到pyc文件里面去。接下来,再对abc.pyc进行import动作,对,并不是编译成PyCodeObject对象之后直接使用,而是先写到pyc里面去,然后将pyc文件的PyCodeObject对象重新在内存中复制出来。 关于python的import机制,我们后面章节会剖析,这里只是用来完成pyc文件的触发。当然得到pyc文件有很多方法,比如使用py_compile模块。 a.py class A: a = 1b.py import a执行b.py的时候,会发现创建了a.pyc。另外关于pyc文件的创建位置,会在当前文件的同级目录下的__pycache__目录中创建,名字就叫做,py文件名.cpython-版本号.pyc
我们使用notepad++打开,以二进制的方式查看一下,发现了一堆看上去毫无意义的数字。
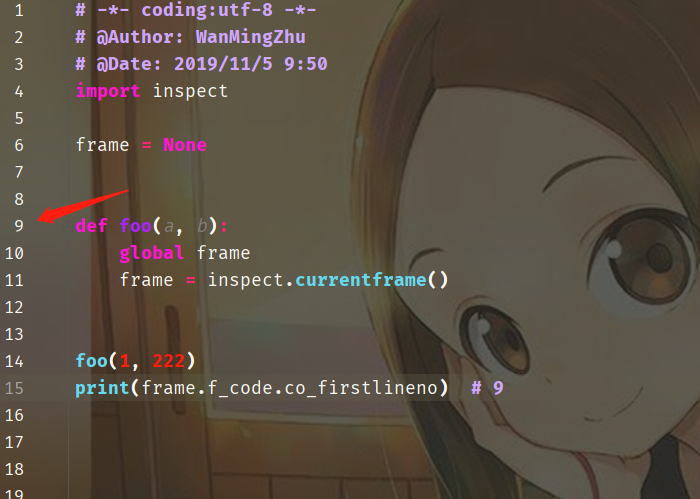
因此python如何解释这些字节流就至关重要了,这也是我们关心的pyc文件的格式。 要了解pyc文件的格式,就必须清楚PyCodeObject对象中的每一个域都代表什么含义,这一点是无论如何也绕不过去的。 回顾一下,PyCodeObject结构体的定义: PyObject_HEAD:真的是一切皆对象,字节码也是一个对象,那么自然要求PyObject这些头部信息 co_argcount:位置参数个数 import inspect frame = None def foo(a, b, c, d): global frame frame = inspect.currentframe() foo(1, 2, 3, 4) # frame是这个函数的栈帧,这个栈帧先不用管 # 总之我们再frame.f_code就可以拿到字节码,这个字节码就是底层的PyCodeObject对象 # 我们再调用一个co_argcount就可以拿到位置参数的个数 print(frame.f_code.co_argcount) # 4co_kwonlyargcount:只能用关键字参数的个数 def foo(a, b, *, c, d): global frame frame = inspect.currentframe() foo(1, 2, c=3, d=4) print(frame.f_code.co_argcount) # 2 print(frame.f_code.co_kwonlyargcount) # 2 # 我们注意到c和d只能使用关键字参数传递,所以是2个 # 如果定义的时候不加*,即使你在在调用的时候都是使用关键字参数传递,也没有用 # 都是属于位置参数。 # co_kwonlyargcount是只能用关键字参数传递的个数co_nlocals:代码块中局部变量的个数,也包括参数 import inspect frame = None def foo(a, b, *, c): name = "xxx" age = 16 gender = "f" c = 33 global frame frame = inspect.currentframe() foo(1, 2, c=3) print(frame.f_code.co_nlocals) # 6 """ 参数有三个,加上局部变量3个,一共6个 下面的c=33中的c和参数的c整体是1个变量 """co_stacksize:执行该段代码块需要的栈空间 import inspect frame = None def foo1(a, b): global frame frame = inspect.currentframe() foo1(1, 222) print(frame.f_code.co_stacksize) # 2co_flags:用于mask,暂时没什么用,在后面介绍函数的时候会用上,因此这个暂时可以不用管 co_firstlineno:代码块在对应文件的起始行
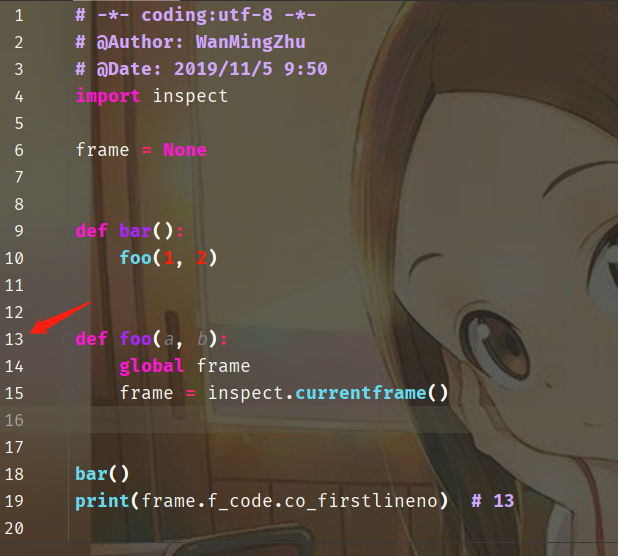
如果foo被函数调用呢?
每个函数都有自己独自的命名空间,以及PyCodeObject对象,所以即便是通过bar调用的,co_firstlineno还是自身的代码块的起始行 co_code:代码块编译成字节码的指令序列,以PyBytesObject的形式存在 import inspect frame = None def bar(): foo(1, 2) def foo(a, b): global frame frame = inspect.currentframe() bar() print(frame.f_code.co_code) # b't\x00\xa0\x01\xa1\x00a\x02d\x00S\x00'co_consts:常量池,PyTupleObject对象,保存代码块中的所有常量。 import inspect frame = None def foo(a, b): name = "satori" global frame age = 16 frame = inspect.currentframe() foo(1, 2) print(frame.f_code.co_consts) # (None, 'satori', 16)co_names:PyTupleObject对象,保存代码块中的所有符号 import inspect frame = None def foo(a, b): name = "satori" global frame age = 16 frame = inspect.currentframe() foo(1, 2) print(frame.f_code.co_names) # ('inspect', 'currentframe', 'frame')co_varnames:代码块中出现的局部变量名 import inspect frame = None def foo(a, b): name = "satori" global frame age = 16 frame = inspect.currentframe() foo(1, 2) print(frame.f_code.co_varnames) # ('a', 'b', 'name', 'age')co_freevars:python实现闭包所需要的东西。 import inspect frame = None def foo(a, b): name = "satori" global frame age = 16 frame = inspect.currentframe() foo(1, 2) print(frame.f_code.co_freevars) # () import inspect frame = None def foo(): name = "satori" age = 16 def inner(): global frame name age frame = inspect.currentframe() return inner foo()() print(frame.f_code.co_freevars) # ('age', 'name')co_cellvars:内部嵌套函数所引用的外部函数的变量 import inspect frame = None def foo(): global frame name = "satori" age = 16 frame = inspect.currentframe() def inner(): name age return inner foo() # 注意到:这里是foo(),不是foo()(),co_freevars需要的是内部函数的栈帧,所以我们要调用两次 # 但这里co_cellvars需要的外部函数foo的栈帧,因此我们只需要调用一次即可,因为global frame是在外部函数当中的 print(frame.f_code.co_cellvars) # ('age', 'name')co_filename:代码块所在的文件名 import inspect frame = None def foo(): global frame name = "satori" age = 16 frame = inspect.currentframe() def inner(): name age return inner foo() print(frame.f_code.co_filename) # C:/Users/satori/Desktop/love_minami/a.pyco_name:代码块的名字,通常是函数名或者类名 import inspect frame = None def foo(): global frame name = "satori" age = 16 frame = inspect.currentframe() def inner(): name age return inner foo() print(frame.f_code.co_name) # fooco_lnotab:字节码指令与python源代码的行号之间的对应关系,以PyByteObject的形式存在 import inspect frame = None def foo(): global frame name = "satori" age = 16 frame = inspect.currentframe() def inner(): name age return inner foo() print(frame.f_code.co_lnotab) # b'\x00\x03\x04\x01\x04\x01\x08\x02\x0e\x04'事实上,python不会直接记录这些信息,而是会记录增量值。比如说:
目前PyCodeObject中的所有属性我们就介绍完了,事实上,还有那么两三个属性我们没有介绍到,因为基本不用,并且通过frame.f_code去获取也根本获取不到。 8.2.4 在python中访问PyCodeObject对象事实上我们已经介绍了一种方法去获取相应的PyCodeObject对象,但是还有没有其他的方法呢? __code__ def foo(): name = "satori" age = 16 code = foo.__code__ # 可以看到,函数本身就提供了获取PyCodeObject对象的接口,直接调用__code__即可 # 此时拿到的就是frame.f_code print(code.co_varnames) # ('name', 'age')compile 在介绍compile之前,先介绍一下eval和exec。 eval:传入一个字符串,然后把字符串里面的内容拿出来。 a = 1 # 所以eval("a")就等价于a print(eval("a")) # 1 print(eval("1 + 1 + 1")) # 3 # 注意:eval是有返回值的,返回值就是字符串里面内容。 # 或者说eval是可以作为右值的,比如a = eval("xxx") # 所以eval里面绝不可以出现诸如赋值之类的,比如 print(eval("a = 3")),那么这个语句等价于print(a = 3),这样显然会出现语法错误的 # 因此eval里面把字符串剥掉之后就是一个普通的值,不可以出现诸如if、def等语句 try: eval("xxx") except NameError as e: print(e) # name 'xxx' is not definedexec:传入一个字符串,把字符串里面的内容当成语句来执行,这个是没有返回值,或者说返回值是None exec("a = 1") # 等价于把a = 1这个字符串里面的内容当成语句来执行 print(a) # 1 statement = """a = 123 if a == 123: print("a等于123") else: print("a不等于123") """ exec(statement) # a等于123 # 注意:'a等于123'并不是exec返回的,而是把上面那坨字符串当成普通代码执行的时候print出来的 # 这便是exec的作用。 # 那么它和eval的区别就显而易见的,eval是要求字符串里面的内容能够当成一个值来打印,返回值就是里面的值 # 而exec则是直接执行里面的内容 # 举个例子 print(eval("1 + 1")) # 2 print(exec("1 + 1")) # None exec("a = 1 + 1") print(a) # 2 try: eval("a = 1 + 1") except SyntaxError as e: print(e) # invalid syntax (, line 1)compile:相当于将两者组合起来 compile则是拿到一个PyCodeObject对象 statement = "a, b = 1, 2" co = compile(statement, "hanser", "exec") print(co.co_name) # print(co.co_filename) # hanser 8.3 pyc文件的生成 8.3.1 创建pyc文件的具体过程前面我们提到,python通过import module进行加载时,如果没有找到相应的pyc或者dll文件,就会在py文件的基础上自动创建pyc文件。所以想要了解pyc文件是怎么创建的,只需要了解PyCodeObject是如何写入的即可。关于写入pyc文件,主要写入三个内容: magic number 这是python定义的一个整数值,不同版本的python会定义不同的magic number,这个值是为了保证python能够加载正确的pyc。比如python3.7不会加载3.6版本的pyc,因为python在加载这个pyc文件的时候会首先检测该pyc的magic number,如何和自身的magic number不一致,则拒绝加载。 pyc的创建时间 这个很好理解,因为编译完之后要是把源代码修改了怎么办呢?因此会判断源代码的最后修改时间和pyc文件的创建时间,如果pyc文件的创建时间比源代码修改时间要早,说明在生成pyc之后,源代码被修改了,那么会重新编译新的pyc,而反之则会直接加载pyc。 PyCodeObject对象 这个不用说了,肯定是要存储的。 文件对象: //位置:Python/marshal.c //FILE是一个文件句柄,可以把WFILE看成是FILE的包装 typedef struct { FILE *fp; //文件句柄 //下面的字段在写入信息的时候会看到 int error; int depth; PyObject *str; char *ptr; char *end; char *buf; _Py_hashtable_t *hashtable; int version; } WFILE;写入magic number和时间: 写入magic number和时间都是调用了PyMarshal_WriteLongToFile,我们来看看长什么样子 void PyMarshal_WriteLongToFile(long x, FILE *fp, int version) { //声明char型的数组,元素个数为4个 char buf[4]; //声明一个WFILE类型变量wf WFILE wf; //内存初始化 memset(&wf, 0, sizeof(wf)); //设置fp,文件句柄 wf.fp = fp; //将buf数组的指针赋值给wf.ptr和wf.buf wf.ptr = wf.buf = buf; //相当于buf的最后一个元素的指针 wf.end = wf.ptr + sizeof(buf); //写错误 wf.error = WFERR_OK; //写入版本信息 wf.version = version; //调用w_long将x也就是版本信息或者时间写到wf里面去 w_long(x, &wf); //刷到磁盘上 w_flush(&wf); } //所以我们看到这一步只是初始化一个WFILE对象,真正写入则是调用w_long static void w_long(long x, WFILE *p) { w_byte((char)( x & 0xff), p); w_byte((char)((x>> 8) & 0xff), p); w_byte((char)((x>>16) & 0xff), p); w_byte((char)((x>>24) & 0xff), p); } //w_long则是将要写入的x一个字节一个字节写到文件里面去。写入PyCodeObject对象: 写入PyCodeObject对象则是调用了PyMarshal_WriteObjectToFile,我们也来看看长什么样子 void PyMarshal_WriteObjectToFile(PyObject *x, FILE *fp, int version) { char buf[BUFSIZ]; WFILE wf; memset(&wf, 0, sizeof(wf)); wf.fp = fp; wf.ptr = wf.buf = buf; wf.end = wf.ptr + sizeof(buf); wf.error = WFERR_OK; wf.version = version; if (w_init_refs(&wf, version)) return; /* caller mush check PyErr_Occurred() */ w_object(x, &wf); w_clear_refs(&wf); w_flush(&wf); } //可以看到,和PyMarshal_WriteLongToFile基本是类似的 //只不过PyMarshal_WriteLongToFile调用的是w_long,而PyMarshal_WriteObjectToFile调用的是w_object static void w_object(PyObject *v, WFILE *p) { char flag = '\0'; p->depth++; if (p->depth > MAX_MARSHAL_STACK_DEPTH) { p->error = WFERR_NESTEDTOODEEP; } else if (v == NULL) { w_byte(TYPE_NULL, p); } else if (v == Py_None) { w_byte(TYPE_NONE, p); } else if (v == PyExc_StopIteration) { w_byte(TYPE_STOPITER, p); } else if (v == Py_Ellipsis) { w_byte(TYPE_ELLIPSIS, p); } else if (v == Py_False) { w_byte(TYPE_FALSE, p); } else if (v == Py_True) { w_byte(TYPE_TRUE, p); } else if (!w_ref(v, &flag, p)) w_complex_object(v, flag, p); p->depth--; }可以看到本质上还是调用了w_byte,但是在这里面我们并没有看到诸如:list、tuple之类的数据的存储过程,注意最后的w_complex_object,关键来了 //源代码很长 static void w_complex_object(PyObject *v, char flag, WFILE *p) { Py_ssize_t i, n; if (PyLong_CheckExact(v)) { long x = PyLong_AsLong(v); if ((x == -1) && PyErr_Occurred()) { PyLongObject *ob = (PyLongObject *)v; PyErr_Clear(); w_PyLong(ob, flag, p); } else { #if SIZEOF_LONG > 4 long y = Py_ARITHMETIC_RIGHT_SHIFT(long, x, 31); if (y && y != -1) { /* Too large for TYPE_INT */ w_PyLong((PyLongObject*)v, flag, p); } else #endif { W_TYPE(TYPE_INT, p); w_long(x, p); } } } else if (PyFloat_CheckExact(v)) { if (p->version > 1) { unsigned char buf[8]; if (_PyFloat_Pack8(PyFloat_AsDouble(v), buf, 1) < 0) { p->error = WFERR_UNMARSHALLABLE; return; } W_TYPE(TYPE_BINARY_FLOAT, p); w_string((char*)buf, 8, p); } else { char *buf = PyOS_double_to_string(PyFloat_AS_DOUBLE(v), 'g', 17, 0, NULL); if (!buf) { p->error = WFERR_NOMEMORY; return; } n = strlen(buf); W_TYPE(TYPE_FLOAT, p); w_byte((int)n, p); w_string(buf, n, p); PyMem_Free(buf); } } else if (PyComplex_CheckExact(v)) { if (p->version > 1) { unsigned char buf[8]; if (_PyFloat_Pack8(PyComplex_RealAsDouble(v), buf, 1) < 0) { p->error = WFERR_UNMARSHALLABLE; return; } W_TYPE(TYPE_BINARY_COMPLEX, p); w_string((char*)buf, 8, p); if (_PyFloat_Pack8(PyComplex_ImagAsDouble(v), buf, 1) < 0) { p->error = WFERR_UNMARSHALLABLE; return; } w_string((char*)buf, 8, p); } else { char *buf; W_TYPE(TYPE_COMPLEX, p); buf = PyOS_double_to_string(PyComplex_RealAsDouble(v), 'g', 17, 0, NULL); if (!buf) { p->error = WFERR_NOMEMORY; return; } n = strlen(buf); w_byte((int)n, p); w_string(buf, n, p); PyMem_Free(buf); buf = PyOS_double_to_string(PyComplex_ImagAsDouble(v), 'g', 17, 0, NULL); if (!buf) { p->error = WFERR_NOMEMORY; return; } n = strlen(buf); w_byte((int)n, p); w_string(buf, n, p); PyMem_Free(buf); } } else if (PyBytes_CheckExact(v)) { W_TYPE(TYPE_STRING, p); w_pstring(PyBytes_AS_STRING(v), PyBytes_GET_SIZE(v), p); } else if (PyUnicode_CheckExact(v)) { if (p->version >= 4 && PyUnicode_IS_ASCII(v)) { int is_short = PyUnicode_GET_LENGTH(v) < 256; if (is_short) { if (PyUnicode_CHECK_INTERNED(v)) W_TYPE(TYPE_SHORT_ASCII_INTERNED, p); else W_TYPE(TYPE_SHORT_ASCII, p); w_short_pstring((char *) PyUnicode_1BYTE_DATA(v), PyUnicode_GET_LENGTH(v), p); } else { if (PyUnicode_CHECK_INTERNED(v)) W_TYPE(TYPE_ASCII_INTERNED, p); else W_TYPE(TYPE_ASCII, p); w_pstring((char *) PyUnicode_1BYTE_DATA(v), PyUnicode_GET_LENGTH(v), p); } } else { PyObject *utf8; utf8 = PyUnicode_AsEncodedString(v, "utf8", "surrogatepass"); if (utf8 == NULL) { p->depth--; p->error = WFERR_UNMARSHALLABLE; return; } if (p->version >= 3 && PyUnicode_CHECK_INTERNED(v)) W_TYPE(TYPE_INTERNED, p); else W_TYPE(TYPE_UNICODE, p); w_pstring(PyBytes_AS_STRING(utf8), PyBytes_GET_SIZE(utf8), p); Py_DECREF(utf8); } } else if (PyTuple_CheckExact(v)) { n = PyTuple_Size(v); if (p->version >= 4 && n < 256) { W_TYPE(TYPE_SMALL_TUPLE, p); w_byte((unsigned char)n, p); } else { W_TYPE(TYPE_TUPLE, p); W_SIZE(n, p); } for (i = 0; i < n; i++) { w_object(PyTuple_GET_ITEM(v, i), p); } } else if (PyList_CheckExact(v)) { W_TYPE(TYPE_LIST, p); n = PyList_GET_SIZE(v); W_SIZE(n, p); for (i = 0; i < n; i++) { w_object(PyList_GET_ITEM(v, i), p); } } else if (PyDict_CheckExact(v)) { Py_ssize_t pos; PyObject *key, *value; W_TYPE(TYPE_DICT, p); /* This one is NULL object terminated! */ pos = 0; while (PyDict_Next(v, &pos, &key, &value)) { w_object(key, p); w_object(value, p); } w_object((PyObject *)NULL, p); } else if (PyAnySet_CheckExact(v)) { PyObject *value, *it; if (PyObject_TypeCheck(v, &PySet_Type)) W_TYPE(TYPE_SET, p); else W_TYPE(TYPE_FROZENSET, p); n = PyObject_Size(v); if (n == -1) { p->depth--; p->error = WFERR_UNMARSHALLABLE; return; } W_SIZE(n, p); it = PyObject_GetIter(v); if (it == NULL) { p->depth--; p->error = WFERR_UNMARSHALLABLE; return; } while ((value = PyIter_Next(it)) != NULL) { w_object(value, p); Py_DECREF(value); } Py_DECREF(it); if (PyErr_Occurred()) { p->depth--; p->error = WFERR_UNMARSHALLABLE; return; } } else if (PyCode_Check(v)) { PyCodeObject *co = (PyCodeObject *)v; W_TYPE(TYPE_CODE, p); w_long(co->co_argcount, p); w_long(co->co_kwonlyargcount, p); w_long(co->co_nlocals, p); w_long(co->co_stacksize, p); w_long(co->co_flags, p); w_object(co->co_code, p); w_object(co->co_consts, p); w_object(co->co_names, p); w_object(co->co_varnames, p); w_object(co->co_freevars, p); w_object(co->co_cellvars, p); w_object(co->co_filename, p); w_object(co->co_name, p); w_long(co->co_firstlineno, p); w_object(co->co_lnotab, p); } else if (PyObject_CheckBuffer(v)) { /* Write unknown bytes-like objects as a bytes object */ Py_buffer view; if (PyObject_GetBuffer(v, &view, PyBUF_SIMPLE) != 0) { w_byte(TYPE_UNKNOWN, p); p->depth--; p->error = WFERR_UNMARSHALLABLE; return; } W_TYPE(TYPE_STRING, p); w_pstring(view.buf, view.len, p); PyBuffer_Release(&view); } else { W_TYPE(TYPE_UNKNOWN, p); p->error = WFERR_UNMARSHALLABLE; } }源代码很长,这里就不一一分析了。虽然长,但是逻辑很简单,就是对应不同的对象、执行不同的写的动作。然而其最终目的都是通过w_byte写到pyc文件中。换句话说,python在往pyc写入list对象时,只是将list中包含的数值或者字符串等对象写到了pyc文件中。同时这也意味着,python在加载pyc文件时,必须基于这些数值或字符串重新构造出list对象。 对于PyCodeObject对象,很显然,w_object会遍历PyCodeObject中的所有域,将这些域依次写入 PyCodeObject *co = (PyCodeObject *)v; W_TYPE(TYPE_CODE, p); w_long(co->co_argcount, p); w_long(co->co_kwonlyargcount, p); w_long(co->co_nlocals, p); w_long(co->co_stacksize, p); w_long(co->co_flags, p); w_object(co->co_code, p); w_object(co->co_consts, p); w_object(co->co_names, p); w_object(co->co_varnames, p); w_object(co->co_freevars, p); w_object(co->co_cellvars, p); w_object(co->co_filename, p); w_object(co->co_name, p); w_long(co->co_firstlineno, p); w_object(co->co_lnotab, p);但是当面对一个PyListObject对象时,会有什么变化呢?没错,会和PyCodeObject一样,w_object还是会遍历,然后将PyListObject对象中的每一个元素依次写入到pyc文件中。 //可以看到PyTupleObject、PyListObject、PyDictObject都是采用了相同的姿势 //注意里面的W_TYPE else if (PyTuple_CheckExact(v)) { n = PyTuple_Size(v); if (p->version >= 4 && n < 256) { W_TYPE(TYPE_SMALL_TUPLE, p); w_byte((unsigned char)n, p); } else { W_TYPE(TYPE_TUPLE, p); W_SIZE(n, p); } for (i = 0; i < n; i++) { w_object(PyTuple_GET_ITEM(v, i), p); } } else if (PyList_CheckExact(v)) { W_TYPE(TYPE_LIST, p); n = PyList_GET_SIZE(v); W_SIZE(n, p); for (i = 0; i < n; i++) { w_object(PyList_GET_ITEM(v, i), p); } } else if (PyDict_CheckExact(v)) { Py_ssize_t pos; PyObject *key, *value; W_TYPE(TYPE_DICT, p); /* This one is NULL object terminated! */ pos = 0; while (PyDict_Next(v, &pos, &key, &value)) { w_object(key, p); w_object(value, p); } w_object((PyObject *)NULL, p); }我们看到无论对于哪一个对象,在写入之前,都会先调用W_TYPE写一个类似于类型的东西,是的,诸如TYPE_LIST、TYPE_TUPLE、TYPE_DICT这样的标识,对于pyc文件的加载起着至关重要的作用。 之前说过,python仅仅将数值和字符串写入到pyc文件。当PyCodeObject写入到pyc之后,所有的数据就变成了了字节流,类型信息就丢失了。然鹅如果没有类型信息,那么当python再次加载pyc文件的时候,就没办法知道字节流中隐藏的结构和蕴含的信息,所以python必须往pyc文件写入一个标识,这些标识正是python定义的类型信息,如果python在pyc中发现了这样的标识,则预示着上一个对象结束,新的对象开始,并且也知道新对象是什么样的对象,从而也知道该执行什么样的加载动作。这些标识也是可以看到的 //marshal.c #define TYPE_NULL '0' #define TYPE_NONE 'N' #define TYPE_FALSE 'F' #define TYPE_TRUE 'T' #define TYPE_STOPITER 'S' #define TYPE_ELLIPSIS '.' #define TYPE_INT 'i' /* TYPE_INT64 is not generated anymore. Supported for backward compatibility only. */ #define TYPE_INT64 'I' #define TYPE_FLOAT 'f' #define TYPE_BINARY_FLOAT 'g' #define TYPE_COMPLEX 'x' #define TYPE_BINARY_COMPLEX 'y' #define TYPE_LONG 'l' #define TYPE_STRING 's' #define TYPE_INTERNED 't' #define TYPE_REF 'r' #define TYPE_TUPLE '(' #define TYPE_LIST '[' #define TYPE_DICT '{' #define TYPE_CODE 'c' #define TYPE_UNICODE 'u' #define TYPE_UNKNOWN '?' #define TYPE_SET ''到了这里可以看到,其实python对于PyCodeObject对象的导出实际上是不复杂的,实际上不管什么对象,最后都为归结为两种简单的形式,一种是数值写入,一种是字符串写入。上面都是对数值的写入,比较简单,仅仅需要按照字节一次写入pyc即可。然而在写入字符串的时候,python设计了一种比较复杂的机制,有兴趣可以自己阅读源码,这里不再介绍。 8.3.2 PyCodeObject的写入 # a.py class A: pass def foo(): pass a = A() foo()我们之前说对于这样的一个py文件,会创建三个PyCodeObject对象,但是写到pyc文件里面的只有一个PyCodeObject,这难道不就意味着有两个PyCodeObject丢失了吗?其实很明显,有两个PyCodeObject对象是位于另一个PyCodeObject对象当中的。因此其实foo和A对应的PyCodeObject对象是位于a.py这个PyCodeObject对象当中的,准确的说是位于co_consts当中 在将一个PyCodeObject对象写入到pyc文件当中时,如果碰到了包含的另一个PyCodeObject对象,那么就会递归地执行写入PyCodeObject对象的操作。如此下去,最终所有的PyCodeObject对象都会写入到pyc文件当中,因此pyc文件当中的PyCodeObject对象也是以一种嵌套的关系联系在一起的。 8.4 python的字节码关于python的字节码,是后面章节剖析虚拟机的重点,现在先来看一下。我们知道python执行源代码之前会对其进行编译得到字节码序列,python虚拟机会根据这些字节码序列来进行一系列的操作,从而完成对程序的执行。 在python中一共定义了130条指令 #define POP_TOP 1 #define ROT_TWO 2 #define ROT_THREE 3 #define DUP_TOP 4 #define DUP_TOP_TWO 5 #define NOP 9 #define UNARY_POSITIVE 10 #define UNARY_NEGATIVE 11 #define UNARY_NOT 12 #define UNARY_INVERT 15 #define BINARY_MATRIX_MULTIPLY 16 #define INPLACE_MATRIX_MULTIPLY 17 #define BINARY_POWER 19 #define BINARY_MULTIPLY 20 #define BINARY_MODULO 22 #define BINARY_ADD 23 #define BINARY_SUBTRACT 24 #define BINARY_SUBSCR 25 #define BINARY_FLOOR_DIVIDE 26 #define BINARY_TRUE_DIVIDE 27 #define INPLACE_FLOOR_DIVIDE 28 ... ...如果使用过dis模块的小伙伴肯定很熟悉,当然这里我们只是先看一下, 后面章节会介绍。 |



 结尾的图片里面的妹子叫hanser,个人非常喜欢的一个up主~~(开婴儿车的老司机)~~,唱歌超好听的,可以去B站关注一下她,能给你带来很多欢乐哦。 链接(hanser哔哩哔哩个人主页):https://space.bilibili.com/11073?from=search&seid=542967129544922757
结尾的图片里面的妹子叫hanser,个人非常喜欢的一个up主~~(开婴儿车的老司机)~~,唱歌超好听的,可以去B站关注一下她,能给你带来很多欢乐哦。 链接(hanser哔哩哔哩个人主页):https://space.bilibili.com/11073?from=search&seid=542967129544922757【本文地址】